NPU 节点使用
NPU 节点 (AI-01) 含 8 张 NPU 卡,卡型号为华为昇腾 910B(Ascend),单卡显存为 64GB HBM。
驱动¶
参考:
Note
集群NPU节点已安装驱动
安装固件¶
# 根据芯片型号选择相应的安装包安装
# 安装firmwire
chmod +x Ascend-hdk-*-npu-firmware_${version}.run
./Ascend-hdk-*-npu-firmware_${version}.run --full
安装驱动¶
# 根据CPU架构 以及npu型号 安装对应的 driver
chmod +x Ascend-hdk-*-npu-driver_${version}_*.run
./Ascend-hdk-*-npu-driver_${version}_*.run --full --install-for-all
npu-smi¶
npu-smi 是 npu 的系统管理工具,可以用于收集设备信息,查看设备健康状态,对设备进行配置以及执行固件升级、清除设备信息等功能。
驱动安装过程中会默认安装 npu-smi 工具。
安装完成后,npu-smi放置在 /usr/local/sbin/ 路径下。
# 查看卡基本信息及运行的进程
$ npu-smi info
# 监控卡使用信息,默认每秒刷新一次
$ npu-smi info watch
NpuID(Idx) ChipId(Idx) Pwr(W) Temp(C) AI Core(%) AI Cpu(%) Ctrl Cpu(%) Memory(%) Memory BW(%)
0 0 89.6 25 0 0 6 5 0
1 0 92.3 26 0 0 3 5 0
2 0 88.6 28 0 0 4 5 0
3 0 90.7 29 0 0 15 5 0
4 0 86.0 28 0 0 5 5 0
5 0 86.7 30 0 0 5 5 0
6 0 109.2 36 0 0 4 62 81
7 0 118.6 36 0 0 2 62 39
ascend-dmi¶
Ascend DMI(Ascend Device Management Interface)工具通过调用底层DCMI(设备控制管理接口)以及AscendCL(Ascend Computing Language,昇腾计算语言)相关接口完成相关检测功能,对于系统级别的信息查询通过调用系统提供的通用库来实现。
ascend-dmi工具主要为Atlas产品的标卡、板卡及模组类产品提供带宽测试、算力测试、功耗测试等功能。
安装
$ ./Ascend-mindx-toolbox_6.0.RC3_linux-aarch64.run --install --install-for-all --nox11
$ source /usr/local/Ascend/toolbox/set_env.sh
带宽测试,测试数据从Host侧传输到Device 0,迭代100次的带宽与总耗时。更多 带宽测试
# 定长模式 $ ascend-dmi --bw -t h2d -d 0 -s 8388608 --et 100 Host to Device Test Device 0: Ascend 910B3. ------------------------------------------------------------------- ID Size(Bytes) Execute Times Bandwidth(GB/s) Elapsed Time(us) ------------------------------------------------------------------- 0 8388608 100 23.566224 355.96 -------------------------------------------------------------------算力测试,测试Device 2,指定算子运算类型默认为fp16,执行次数为6千万的算力。更多 算力测试
$ ascend-dmi -f -d 2 --et 60 ----------------------------------------------------------------------------------------- Device Execute Times Duration(ms) TFLOPS@FP16 Power(W) ----------------------------------------------------------------------------------------- 2 360,000,000 1988 313.531 223.300003 -----------------------------------------------------------------------------------------
CANN¶
异构计算架构CANN(Compute Architecture for Neural Networks)是昇腾针对AI场景推出的异构计算架构,向上支持多种AI框架,包括MindSpore、PyTorch、TensorFlow等,向下服务AI处理器与编程,发挥承上启下的关键作用,是提升昇腾AI处理器计算效率的关键平台。同时针对多样化应用场景,提供多层次编程接口,支持用户快速构建基于昇腾平台的AI应用和业务。
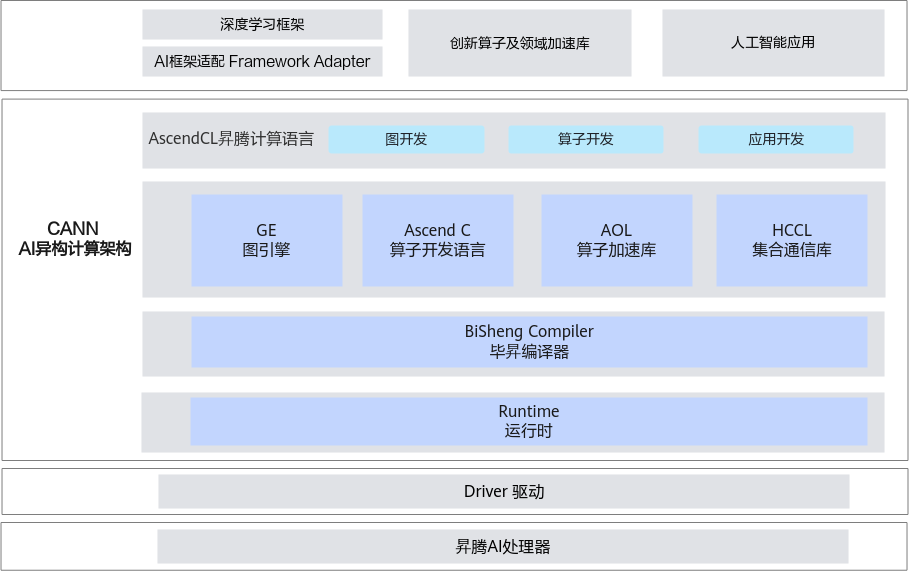
参考
Note
集群已安装CANN
安装 toolkit¶
# 安装toolkit 以arm为例
chmod +x Ascend-cann-toolkit_${version}_linux-aarch64.run
./Ascend-cann-toolkit_${version}_linux-aarch64.run --install --install-for-all
source /usr/local/Ascend/ascend-toolkit/set_env.sh
安装 kernel¶
# 根据芯片型号选择相应的安装包安装
# 安装 kernel
chmod +x Ascend-cann-kernels-*_${version}_linux.run
./Ascend-cann-kernels-*_${version}_linux.run --install --install-for-all
pytorch for npu¶
预编译包¶
https://www.hiascend.com/document/detail/zh/Pytorch/60RC2/configandinstg/instg/insg_0001.html,这个链接中下载 torch 和 torch_npu 预编译包(whl)。
这里选择的pytorch 版本为 2.3.1,python 版本为 3.9(集群默认python版本),系统架构为 aarch64。可以根据自己的python版本、需要的pytorch版本选择对应版本的 python 包下载安装。
查看 CANN 版本 ls /usr/local/Ascend/ascend-toolkit/。
# 下载PyTorch安装包
$ wget https://download.pytorch.org/whl/cpu/torch-2.3.1-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 下载torch_npu插件包
$ wget https://gitee.com/ascend/pytorch/releases/download/v6.0.rc2-pytorch2.3.1/torch_npu-2.3.1-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 安装命令
$ pip3 install torch-2.3.1-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
$ pip3 install torch_npu-2.3.1-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
可安装的版本 https://pypi.org/project/torch-npu/#history
$ pip3 install torch_npu==2.3.1 "numpy<2.0"
import torch 出现报错 Failed to load PyTorch C extensions,可尝试设置环境变量 export LD_LIBRARY_PATH=$HOME/.local/lib/python3.9/site-packages/torch_npu/lib:$LD_LIBRARY_PATH
安装后测试 python3 -c "import torch;import torch_npu; a = torch.randn(3, 4).npu(); print(a + a);"。
自行编译 torch_npu¶
版本配套关系,这里以 v2.1.0-6.0.rc2 为例。
git clone -b v2.1.0-6.0.rc2 https://gitee.com/ascend/pytorch.git
cd pytorch
bash ci/build.sh --python=3.9
pip3 install --upgrade --upgrade dist/torch_npu-2.1.0.post7+gitunknown-cp39-cp39-linux_aarch64.whl
Warning
经测试,集群上使用预编译的 torch_npu 使用会报错,需自行编译。
使用集群预安装 torch_npu¶
$ module load arm/torch_npu/2.1.0.post7-py3.9
测试使用¶
# 交互模式进入NPU节点
$ dsub -q interactive --label AI -I bash
# 查看卡是否存在
$ lspci | grep d802
# 加载相关环境
$ source /etc/profile
$ source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 查看卡信息
$ npu-smi info
# 测试 pytorch 安装是否正常
$ python3 -c "import torch;import torch_npu;print(torch_npu.npu.is_available())"
# 测试使用 torch 运算,如果出现下面的运算结果,表明 pytorch 框架与插件安装成功
$ python3 -c "import torch;import torch_npu; a = torch.randn(3, 4).npu(); print(a + a);"
tensor([[-0.6066, 6.3385, 0.0379, 3.3356],
[ 2.9243, 3.3134, -1.5465, 0.1916],
[-2.1807, 0.2008, -1.1431, 2.1523]], device='npu:0')
参考
代码迁移¶
已有的基于英伟达 cuda 的 pytorch 代码可以通过更改少量的代码迁移到 npu 上运行,相关方法见:
本文阅读量 次本站总访问量 次